The question if stacking all subs at once will give you the same result as stacking subs into subsets and stack those subsets together is one that pops up quite often. You might have a lot of frames to stack and you’re computer has trouble handling it, or you might have data from several nights and want to combine them; are you better of stacking all individual subs together or can you just stack each subset that you stacked every night?
To answer this question I did a test on my data I have from my Sagittarius Triplet picture, since I have 75 subs to work with. But before we do let’s think for a sec about what’s really happening when we stack subs together and how that is impacted by stacking subsets.
What happens when we stack subsets
To understand what happens when we are stacking subsets and how that impacts the total stack we need to remember what is going on when we stack and how this benefits the SNR and dynamic range.
Perhaps the most important thing to realise is the way stacking benefits SNR. Random noise will have a Gaussian distribution, which means it’s average will approach the central value of this distribution. In case of random noise this should be zero, so it cancels out the noise. In order for this to work you need enough samples to get a nice symmetric Gaussian distribution. If you take few random samples (stack fewer frames) this noise distribution won’t be a nice symmetric normal distribution and thus won’t cancell out as well as when you add a lot of samples and get a very good and clear Gaussian distribution.
In other words; if you stack fewer frames the (random) noise cancellation will be less accurate, and that is why we benefit from stacking more frames.
So if you stack subsets you’ll loose this benefit, hurting the SNR in your final stack.
An analysis of stacking subsets
To put the theories to the test I’ve analysed the effects of stacking subsets and compare them to the equivalent stack with the same # of subs.
Let’s look at noise levels first;
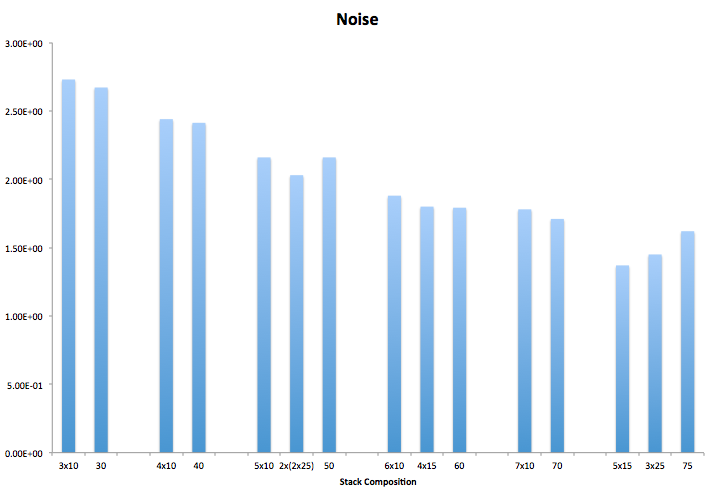
When we look at the noise levels we can see that overall it supports the idea that noise levels will be lower in the ‘total-stack’ than the subsets stacked together. We do see the reverse at 75 frames for some reason which I can’t explain by just looking at the noise level. So let’s look at overall SNRWeight;
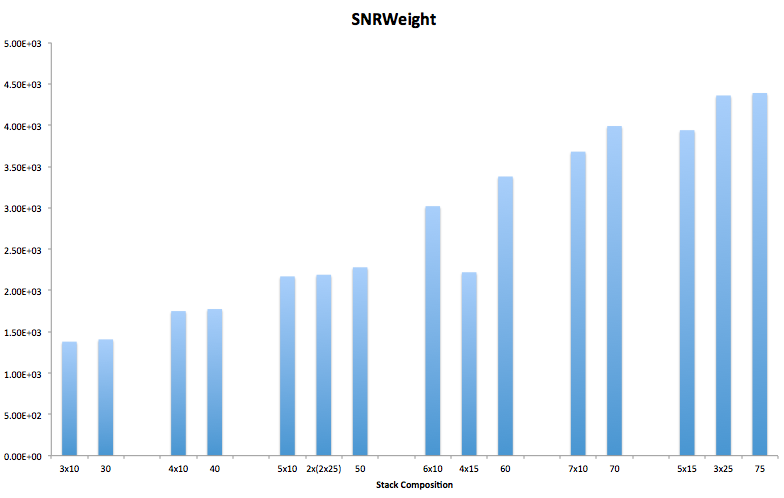
Apart from 1 measurement that seems of, we do see a consistent picture; stacking all frames together is better than stacking subset. We now also see this at 75 frames, so whatever caused the noise level to be higher than a subset, also caused the signal to be higher (even stronger) resulting in still better SNRWeight.
Conclusion on stacking subsets versus stacking all subs at once
The conclusion is simple enough; unless you have real good reasons to stack a subset, you are better of by stacking all subs at once.

Hi! I love your experiments and I want to do some tests by myself!
Have you ever written an article about how to extract these data? I can provide my results if you are interested, but it would be necessary to adopt your methodology draw conclusions and compare results
Here is how I try to figure out these numbers
0. from raw (single frame) or fits files (stack result): open with Photoshop, but I don’t know how to stretch the image properly (linearly, I guess, but I do not find the param in photoshop)
1. I don’t have of a good/reliable method to calculate noise and SNR: I usually open the frame with Photoshop, select a region and look at the figures in the histogram, this is very much dependent on the region you are selecting and, since selection is done manually, I’m not even sure this is reliable to compare two images
thank you for all the work you are doing, really inspiring!
Hi Michele,
First of all my apologies for the late reply to your comment. Somehow this one slipped through and I only read it now 😉
As for the methodology question; that’s an excellent point and I’ll write an article about it soon!
Most of the time I’m just using the statistics/measurements that are available in PixInsight. And like you mentioned this of course should be done on raw data (linear for sure, but even not processed at all or else you can’t compare). But with so many different metrics, and programs I’ll do an article on what they all mean and how you can use them to analyse your pictures
thanks again for your comment!
Hi and thanks for an interesting article 🙂
Usually I preprocess each night’s Lights separately with a Master SuperBias, a Master Dark and a Master Flat. I then sometimes Cosmic Correct them (if necessary), and I finally Debayer them (as I’m shooting with a DSLR).
I keep each night’s results of preprocessed subs separately when done with the above.
When it then comes to stacking all these subs together, I get totally get your point and I usually stack all subs in one go.
However I’m now looking into 8 hours in creating drizzle files, and then 8 hours in creating normalization files, and then 8 hours of integrating everything just to have the drizzle files update – so I can finally spend at least 8 hours in finalizing with Drizzle Integration 😜
So as you can imagine I’m growing long gray hairs on my balls during that process 😬
I have several hundreds of subs per night and counting – so that’s why I’m now considering stacking each night separately (200-700 subs per night) and then stacking the stacks across nights.
It’s a little more than comparing at set of max 70 subs… 😏
Any comments or thoughts on doing that? Whould it still make a significant difference when we’re talking that amount of subs going into each subset do you think?
Obviously I’m working in Pixinsight but on a fairly old iMac27 with 32 ram but a slow dual core i5 cpu…
Also my tracking is not precise enough to take really long exposures which is why I stay at only 30 sec exposures resulting in a lot of subs…
I’m holding my breath on a guide scope for more precise autoguiding as I don’t want to leave a computer in the garden in front of a lot of apartments, so for now I’m only guiding with GoTo…
I tried to spin up a Microsoft Azure in the cloud with 8 cores and enough ram (can be scales to anything if you have the money) but I didn’t gain much time taking the upload of subs into the calculation…
Sorry for long comment 😂
/Tomas
that would be an interesting (although ‘hairy’;)) test to do. I would say the difference will be not that big and you fall in the category of people that have good reason to stack in subsets 😉
If you have that any subs in a subset than I really expect the difference to be minimal.
Interesting to hear you tried cloud computing for this! I guess the money is better spent on getting guiding going and stable though, that’ll give you probably the most benefit for the $$ 😉